
拆解CANN:当华为决定打开算力的「黑盒」
拆解CANN:当华为决定打开算力的「黑盒」最近,在 AI 基础算力上重磅频出的华为,又亮出了一张王牌:昇腾的底层基础软件,CANN 全面开源开放。昇腾宣布将通过一系列新举措,持续支持开发者在 AI 模型、算子、内核、底层资源等多个层级进行自主优化与自定义开发。通过开放共建,一个新兴的 AI 算力生态正在快速崛起,改变计算架构领域本已固化的格局。
来自主题: AI资讯
10103 点击 2025-12-20 10:05
 搜索
搜索
最近,在 AI 基础算力上重磅频出的华为,又亮出了一张王牌:昇腾的底层基础软件,CANN 全面开源开放。昇腾宣布将通过一系列新举措,持续支持开发者在 AI 模型、算子、内核、底层资源等多个层级进行自主优化与自定义开发。通过开放共建,一个新兴的 AI 算力生态正在快速崛起,改变计算架构领域本已固化的格局。
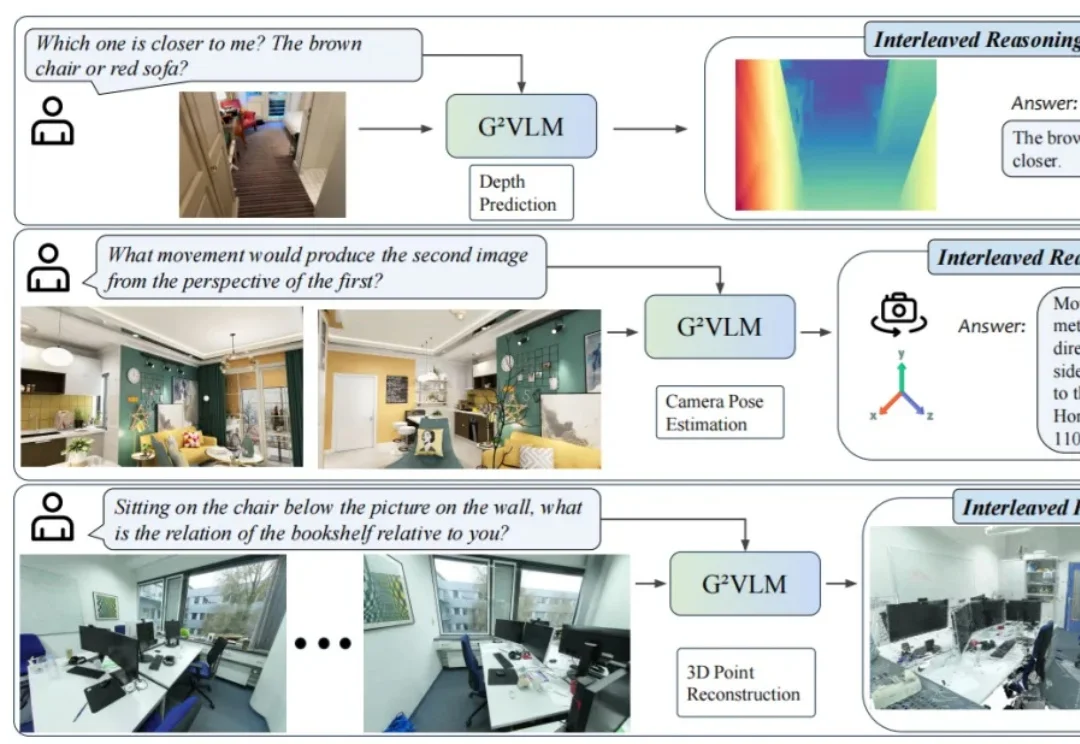
近日,24 岁的 00 后博士生胡文博和所在团队造出一款名为 G²VLM 的超级 AI 模型,它是一位拥有空间超能力的视觉语言小能手,不仅能从普通的平面图片中精准地重建出三维世界,还能像人类一样进行复杂的空间思考和空间推理。
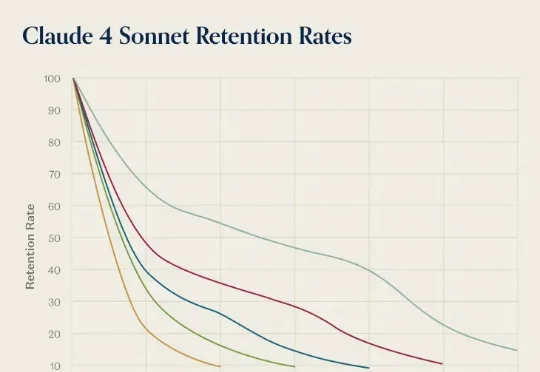
前几天,AI 推理服务供应商 OpenRouter 发布了一份报告《State of AI》,基于平台上 60 多家提供商的 300 多个模型,100 万亿个 token 的交互数据,对 LLM 的实际应用情况进行了分析。报告中,提到了一个「灰姑娘水晶鞋效应」,特别有意思。研究者在分析用户留用数据时发现一个现象:AI 模型发布第一个月进来的用户,往往比后来进来的用户留存率更高。
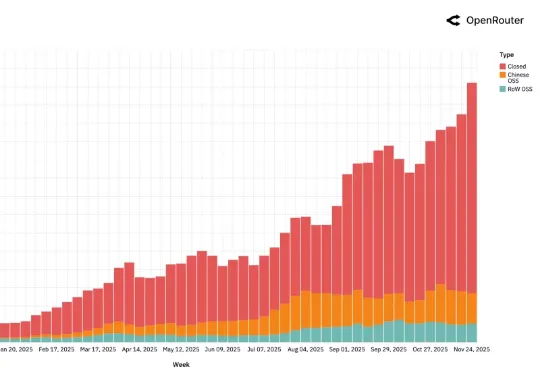
AI 领域迄今最大规模的用户行为实录,刚刚发布了。这是全球模型聚合平台 OpenRouter 联合硅谷顶级风投 a16z 发布的一份报告,基于全球 100 万亿次真实 API 调用、覆盖 300+款 AI 模型、60+家供应商、超过 50% 非美国用户 。

最近,Google Research 发布了一篇 Blog《Titans + MIRAS:帮助人工智能拥有长期记忆》。它们允许 AI 模型在运行过程中更新其核心内存,从而更快地工作并处理海量上下文。
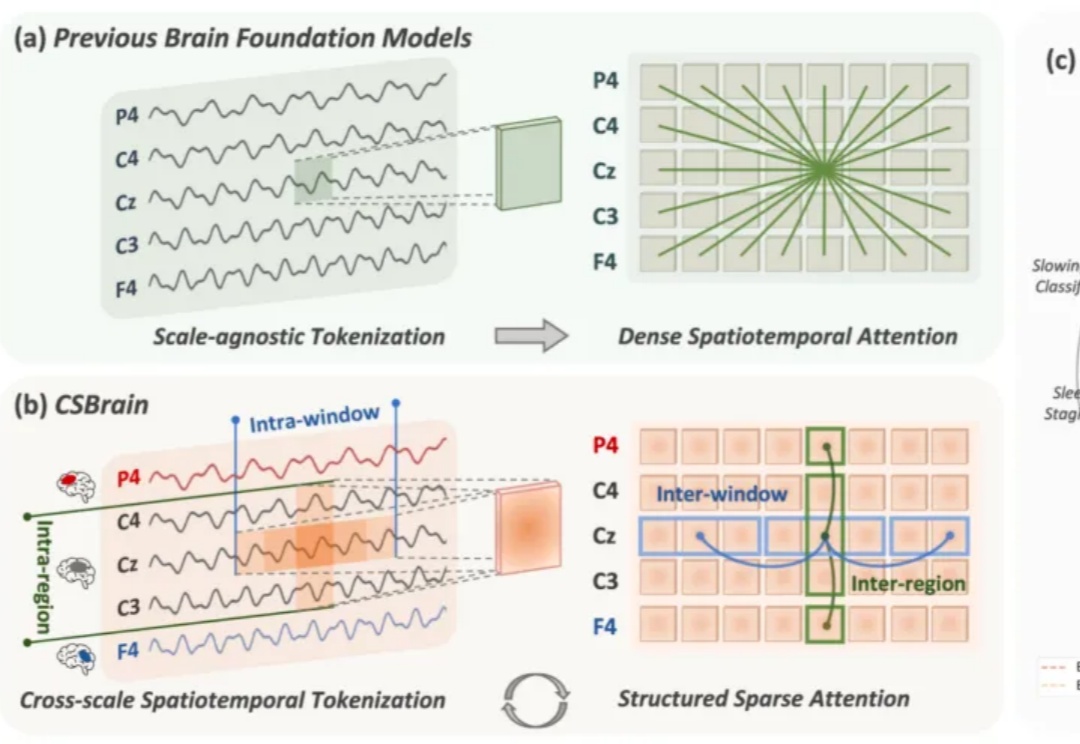
脑机接口(Brain-Computer Interface, BCI)被视为连接人类智能与人工智能的终极界面。要真正实现这一愿景,核心在于高精度的脑信号解码,即让通用 AI 模型能够真正「读懂」复杂多变的脑活动。
作为连接 AI 模型与广阔数字生态的「神经中枢」,MCP 协议已然成为智能体(AI Agent)不可或缺的基础设施。然而,长期以来,MCP 的交互仅限于文本和结构化数据,这种「盲人摸象」般的体验限制了更复杂应用场景的落地。

近日,在 CNCC2025 大会上,郑波首次公开了淘宝全模态大模型的最新进展,并系统介绍了多模态智能在淘宝 AIGX 技术体系的研究应用。另外,结合 AI 模型技术在淘宝应用中的实践,他认为,「狭义 AGI 很可能在 5-10 年内到来。」
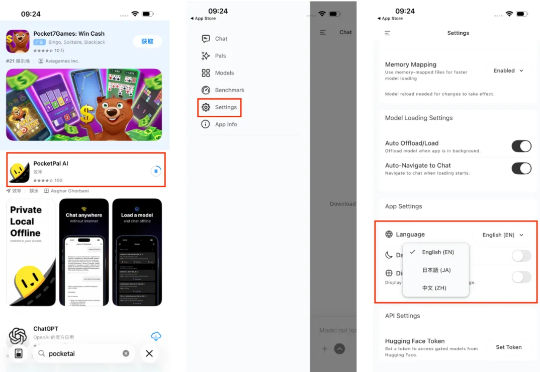
在 iPhone 上部署端侧 AI 模型,成了互联网的新显学。在 iPhone 上体验端侧模型,门槛其实不算高。打开 App Store,搜索 PocketPal AI,下载安装。如果不习惯英文界面,可以在设置 (Setting) 里找到语言 (Language) 选项,切换成中文。

我想聊个反向操作:咱们普通人,如何用有限的资源,轻松驯服一个 AI 模型,让它变成我们专属的垂直领域小能手?主角,就是最近华为刚刚开源的一个大小仅为 1B 的模型 openPangu-Embedded-1B,它不仅全面领先同规格模型,甚至与更大规模的 Qwen3-1.7B 也难分伯仲。